

No es un secreto que las aplicaciones de hoy en día generan una gran cantidad de datos y sumado a eso, cada vez tenemos más aplicaciones independientes que van produciendo datos de forma aislada, por tal motivo, llegara un momento en que los datos están distribuidos en varias base de datos, por lo que recuperar información relevante y consistente, nos obliga a crear complejos procesos de extracción y cargado de datos (ETL) para integrarlos en una única fuente confiable para finalmente sea analizada y explotable, sin embargo, como analizaremos en este artículo, este enfoque tiene grandes problemas, entre los que destaca los complicados procesos de extracción y los múltiples procesos ETL que deben de correr una y otra vez para obtener diferente información para diferentes análisis o reportes.
Antecedentes
Cuando las herramientas como Business Intelligence (BI) comenzaron a ponerse de moda, predominaban las aplicaciones monolíticas, donde cada aplicación podía contener una gran cantidad de información sobre una parte del negocio:
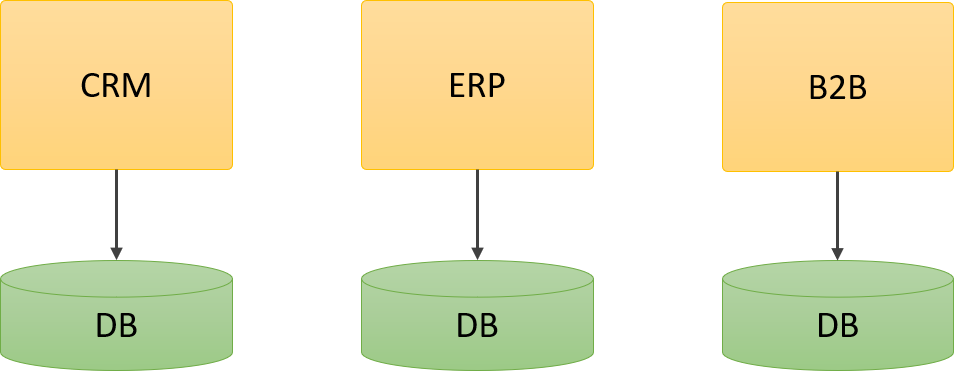
Debido a que los sistemas eran grandes silos datos, era muy simple crear procesos ETL para extraer información de estos sistemas y crear los famosos Data warehouses o almacenes de datos, desde los cuales las herramientas de BI generaban sus reportes:
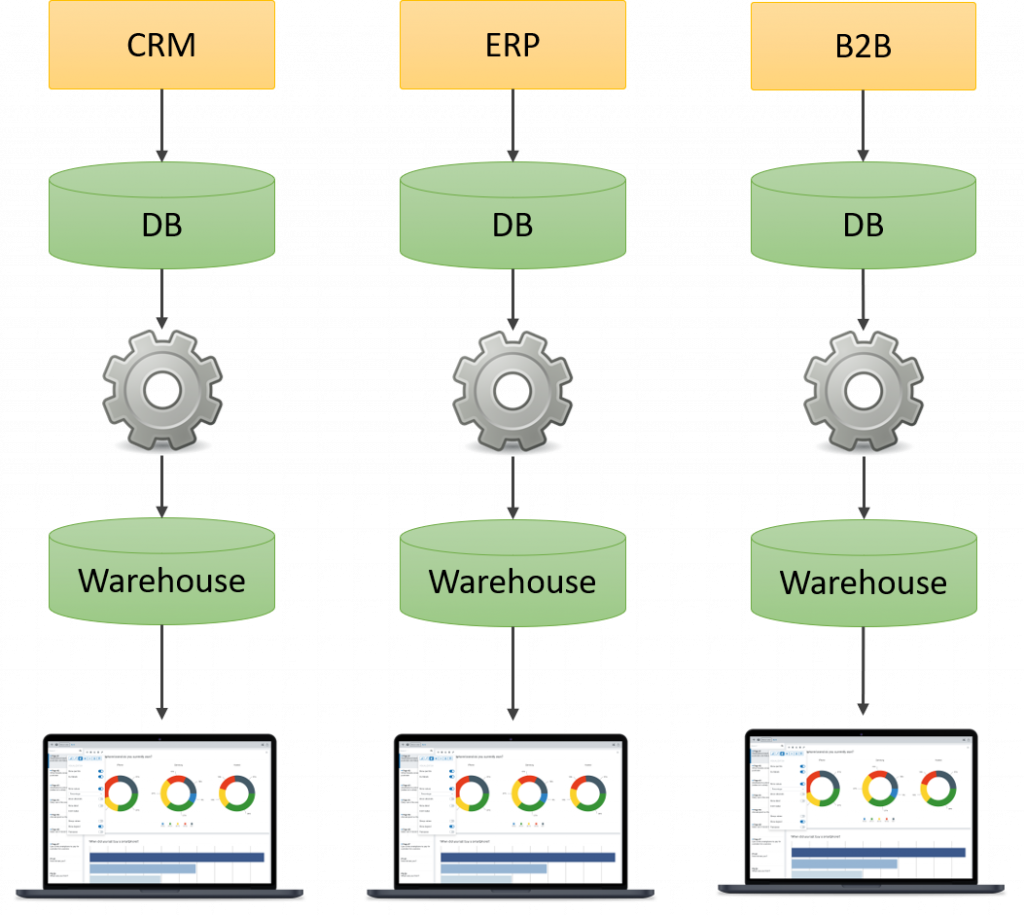
A pesar de que esto es suficiente para muchas empresas, el problema llega cuando se requieren reportes más complejos, donde la información se recolecta de múltiples sistemas para generar un solo reporte, creando una sobre carga de las bases de datos transaccionales, pues múltiples procesos extraen información para diferentes almacenes de datos:
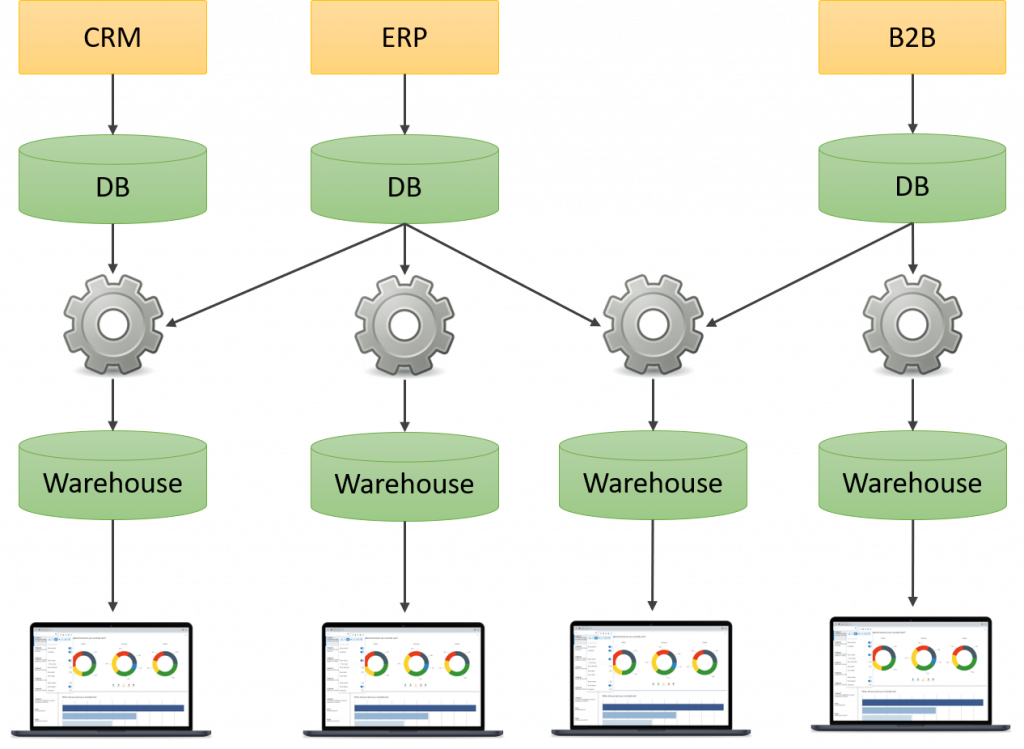
Lo que estamos viendo en la imagen anterior es un caso muy común que he visto en muchas empresas, donde tiene varios procesos ETL que extraen información del mismo sistema, pero como son varios procesos, los tiene que programar a diferentes horas de la noche o del día para que no corran en simultaneo.
Si prestamos atención en la imagen anterior, podrás observar que el ERP es utilizado por 3 procesos ETL para crear diferentes almacenes de datos, y muy probablemente los 3 procesos ETL consulten prácticamente la misma información, pero la procesen de forma diferente, entonces, como la procesan diferente según su objetivo, hace necesario crear cuantos procesos ETL sea necesario para satisfacer todas las necesidades del negocio, lo cual, queda claro que no es para nada eficiente.
¿La solución es un Stagin Area?
Dada la problemática anterior, quizás los más experimentados digan, bueno, pues creamos un Stagin Area en donde volquemos todos los datos y sobre esa base de datos corremos los procesos ETL. Veamos como quedaría:
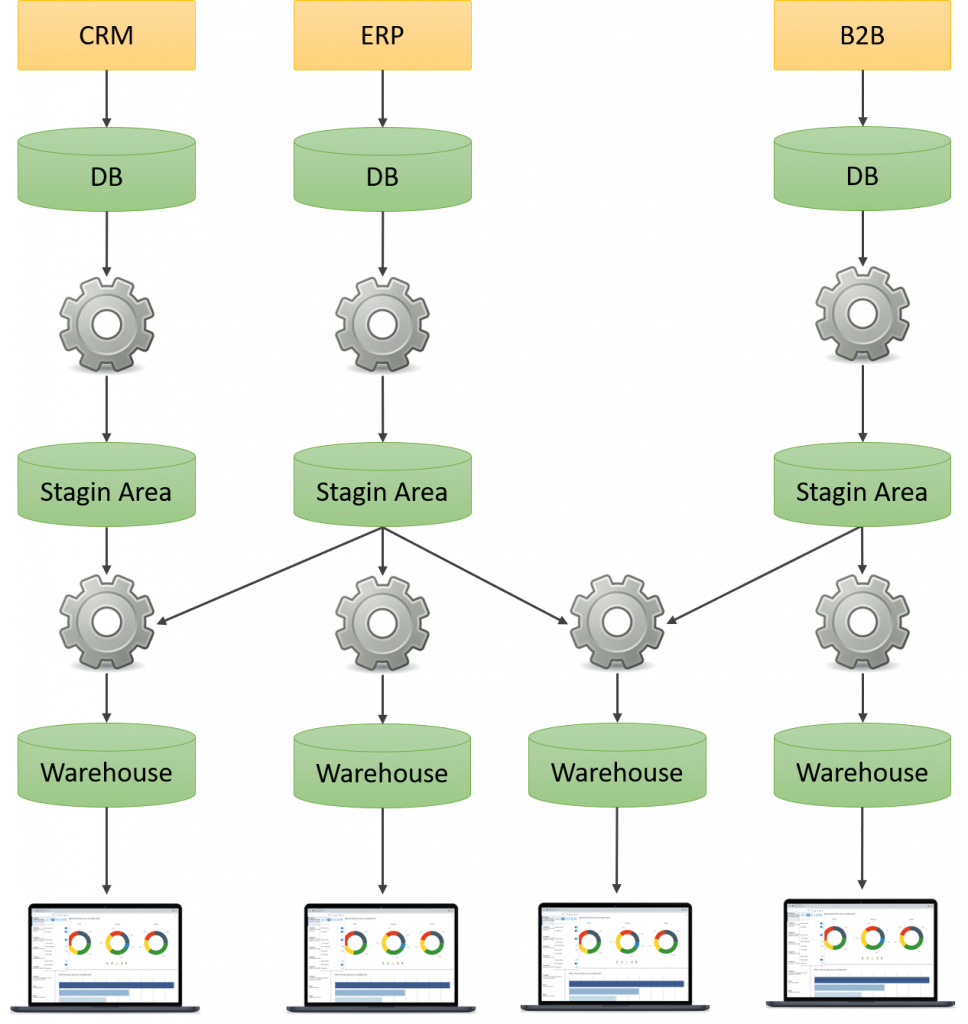
En esta nueva arquitectura tenemos proceso de extracción que solo extraen los datos una vez de los sistemas transaccionales y los dejan en los Stagin Area, los cuales al nos ser transaccionales, permite que múltiples procesos ETL se conecten a ellos para extraer la información y crear sus propios almacenes de datos. Este enfoque tiene varias ventas:
- Extraemos la información una sola vez de los sistemas transaccionales.
- Permite que los procesos ETL se conecten a los Stagin Area a la hora que sea sin comprometer la operatividad del negocio.
- Tenemos un mejor control sobre los procesos que extraen información de los sistemas transaccionales.
Entonces estarás pensando, listo, problema resuelto, cerremos todo y vamos a casa a descansar, sin embargo, hay una pequeña que no hemos sumado a la ecuación…. Los microservicios y las arquitecturas distribuidas, que es aquí donde todo comienza a complicarse, pues en lugar de tener grandes fuentes de datos, tenemos múltiples fuentes, donde cada una cuenta una parte de la historia y para poder tener toda la historia, necesitamos recopilar información de múltiples puntos.
Datalake
El problema ( o la ventaja, depende de como lo veas) es que en arquitecturas de microservicios no tenemos enormes sistemas desde los cuales obtener los datos, si no que es necesario recopilar datos de varias fuentes solo para poder crear un reporte:
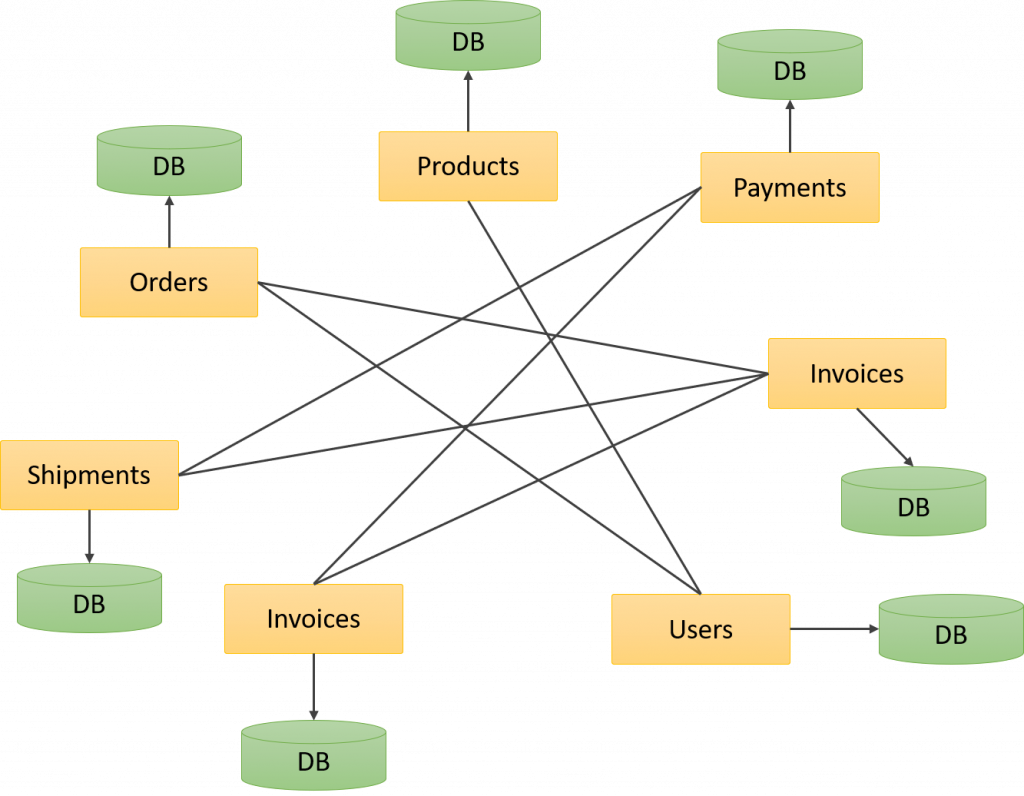
Bajo esta arquitectura se hace impráctico tener múltiples Stagin Area, ya que se tendrían que mantener demasiadas bases de datos, por eso, se propone los Datalake o Lagos de datos, los cuales cambian considerablemente la forma en que los datos se extraen y se procesan.
Un lago de datos es básicamente un vertedero donde son las mismas aplicaciones quienes dejan los datos, en lugar de ser extraídos por un proceso, por otra parte, un Datalake es único, esto quiere decir todas las aplicaciones dejan los datos en el mismo lugar. Creando un lago de datos donde los demás procesos se pueden servir.
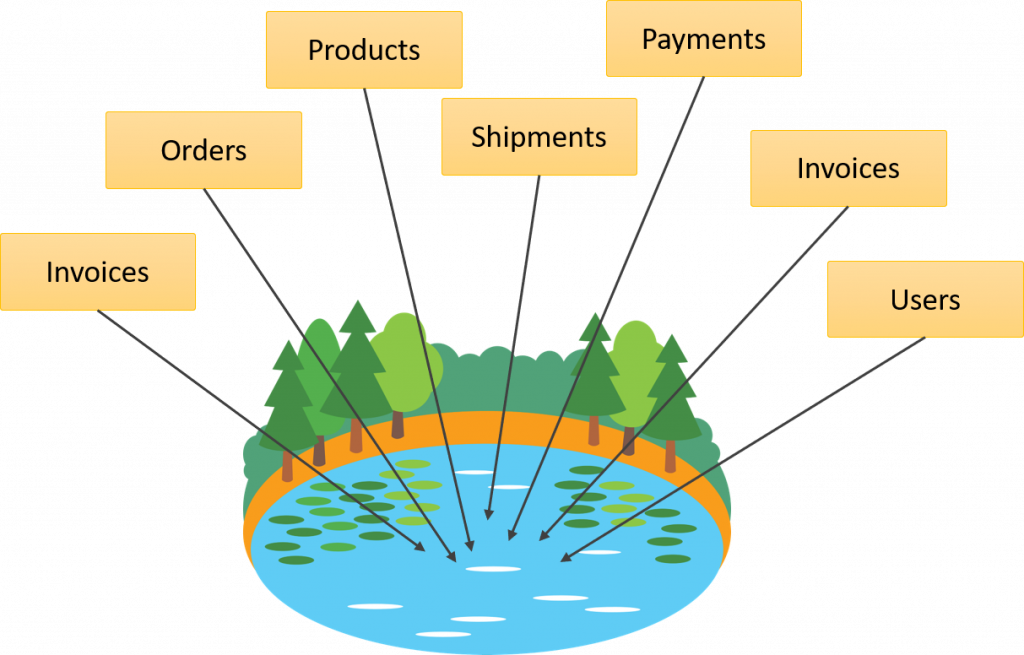
Este enfoque puede resultar controversial, pero a medida que avancemos en este artículo, iremos resolviendo algunas dudas que puedan surgir, así que por lo pronto, solo ve analizando esto.
Lo primero que debemos entender respecto al Datalake es que son las mismas aplicaciones las que deciden que información mandar al lago y el formato de la misma, por que cada aplicación es dueña de su parte del lago. De la misma forma, esta tiene la libertada de agregar, quitara o modificar la estructura de la misma, ya que cada aplicación determina que y como la información se envía al Datalake. Aunque claro, siempre será mejor no hacer cambios demasiados bruscos.
Otro aspecto del lago es que la información es incremental y no está procesada, esto quiere decir que los sistemas van depositando solamente la nueva información (aun que podrían borrar y cargar toda la data), pero al mismo tiempo, la información no está procesada al momento de dejarla en el lago, si no que se deja en bruto.
En este nuevo enfoque son los interesados los encargados en buscar que información les sirve y cual no, al mismo tiempo que se puede obtener información de múltiples aplicaciones de forma simultánea. Ha esto yo le llamo los ríos del lago, ya que cada interesado deshoja del lago la información que le sirve para su propósito para dejarla en un data warehouse ya procesada:
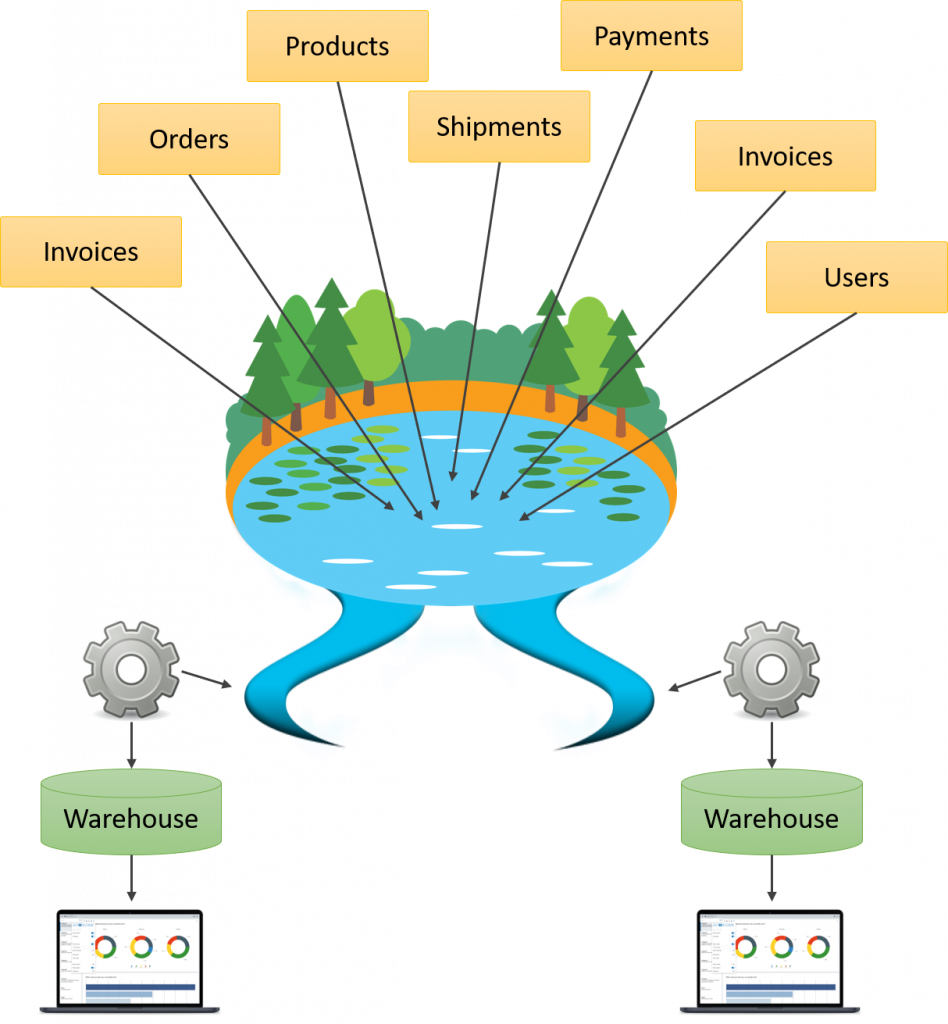
Este enfoque es especialmente útil en entornos de Big Data y análisis de datos, ya que todos los sistemas van depositando la data en bruto en un mismo lugar, lo que facilita para que los científicos de datos puedan explotar la información, además, es posible contrastarla con la data de los demás sistemas.
Reservas respecto a la seguridad
Uno de los aspectos más cuestionados sobre este enfoque es la seguridad de los datos, ya que una persona con acceso total al lago tiene visión completa de lo que pasa en todos los sistemas, lo cual no es una observación menor, por lo que hay que tener especia cuidado sobre los accesos que damos a este. No hay una formula clara o única para resolver esto, salvo que limitar bien el acceso al lago y tener acuerdo de confidencialidad bien estipulados.
Hola Oscar, es un tema muy interesante, tienes mas información?
Ejemplo de alguna posible solución, gracias.
No tengo información a la mano, salvo decirte que hay varios libro de Datalake para Azure y AWS, sería cuestión de que googles un poco y los encontrarás.
buenisimo, tal vez comentar sobre el datalake de AWS
En realidad tambien lo tiene Azure