

Seguramente todos nos hemos encontrado alguna vez con que la petición a un servicio o un recurso de internet nos retorna con un Timeout, lo que significa que el servidor ha tardado tanto en responder que, el navegador o el cliente que estamos utilizando para consumir el recurso corta la comunicación, lo cual es muy frustrante, sin embargo, el Timeout es una de las estrategias más importantes para proteger la salud de nuestro servidor.
Problemática
Seamos sinceros, casi todo nos hemos topado con un Timeout al momento de consumir un servicio, y en lugar de controlar el error y hacer algo en consecuencia para que todo nuestro servicio no falle, simplemente aumentamos el Timeout. En algunos casos solamente le agregamos unos segundos adicionales y en el peor de los casos dejamos el Timeout en indefinido, lo que es una muy mala práctica.
Desafortunadamente, como programadores siempre buscamos la solución más fácil y la que requiere un menor esfuerzo de nuestra parte, lo cual nos lleva a establecer un Timeout indefinido, sin embargo, da igual si le pones 1 minuto o 10hrs, o indefinido, al final, si un servicio no responde a los pocos segundo, lo mas seguro es que no lo haga nunca, lo que provoca que no solo no obtengamos la respuesta del servidor, si no que ahora acarreamos un problema crítico a nuestra aplicación, la cual analizaremos con el siguiente ejemplo.
Imagina que estas construyendo un servicio para autorizar créditos. Este servicio debe de recibir como parte de la solicitud del crédito, los datos del cliente que lo esta solicitando, y luego deberá de consumir un servicio externo para validar el historial crediticio del cliente, según su calificación, se le podrá ofrecer o declinar el préstamo:
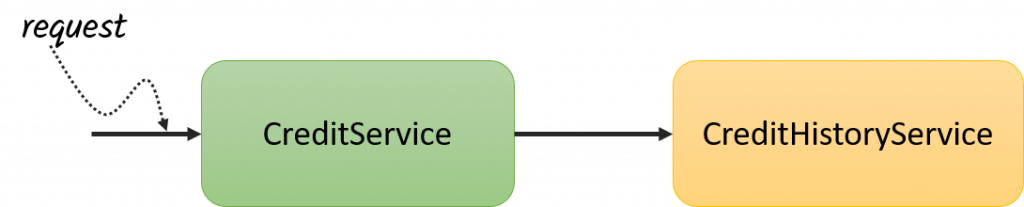
En este caso, nuestro servicio (CreditService) recibirá la petición de la solicitud de crédito y luego llamará al servicio de consulta del historial crediticio (CreditHistoryService), si todo sale bien, nuestro servicio obtendrá la respuesta del servicio anterior y podrá determinar si puede o no, ofrecerle el crédito a nuestro cliente.
Ahora bien, en una arquitectura distribuida donde tenemos múltiples servicios distribuidos por la red, siempre existirá la posibilidad de que uno de estos no esté disponible o simplemente nos arroje un Timeout, lo cual rompe por completo nuestro flujo, pues al no tener respuesta del servicio de historial crediticio, el error se propaga hasta al cliente, por lo que no será posible dale una respuesta:
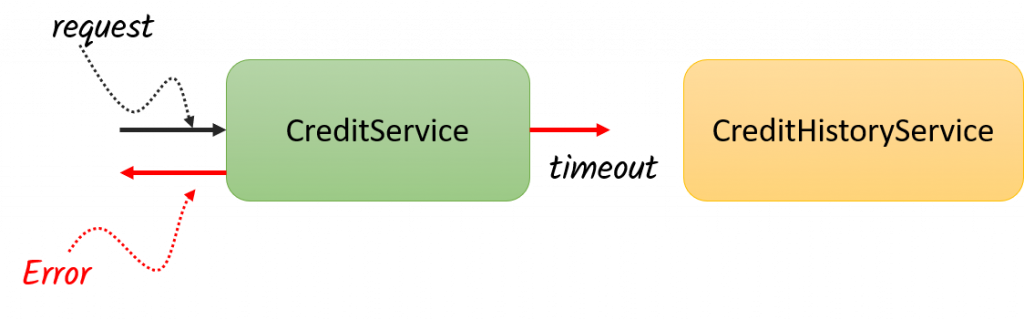
Cual es el problema aquí, que como no queremos batallar y queremos reducir al máximo la posibilidad de error y garantizar el happy path, incrementamos el Timeout del servicio, lo cual es correcto si se hace dentro de un periodo de tiempo considerable, sin embargo, solomos abusar de esto y poner tiempo larguísimos como de 1 minuto o indefinido, lo que provoca que nuestro servicio se comience a saturar de peticiones entrantes y al no tener respuesta del servicio, nuestra aplicación se comienza a saturar de hilos:
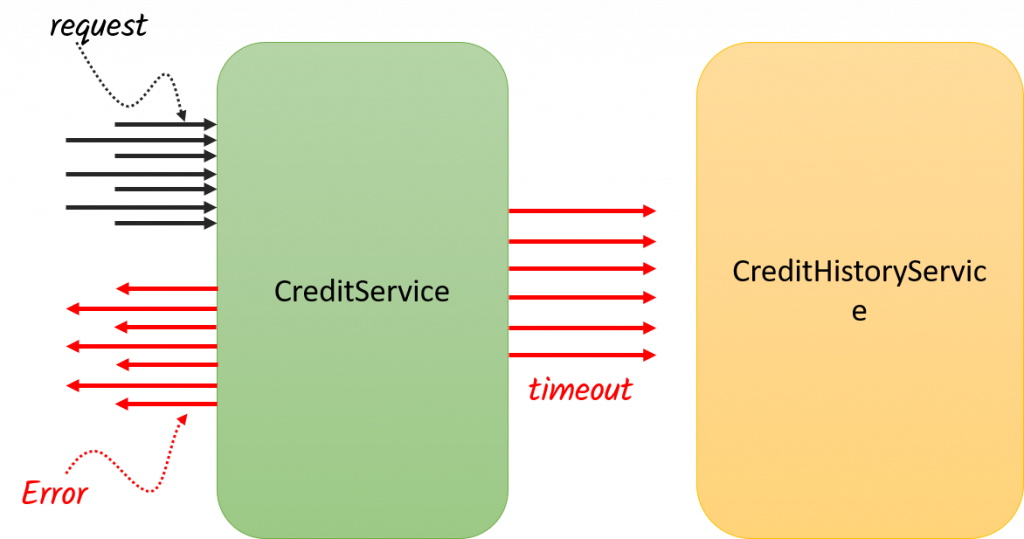
Podrás ver que ahora los hilos se comienzan a acumular en nuestro servicio, ya que al no tener respuesta del servicio, no podemos concluir con la ejecución, y tras un largo periodo de tiempo o hasta que el cliente decida cortar la comunicación, veremos que todas las ejecuciones terminaran fallando, y en el peor de los casos, nuestra aplicación podrá verse seriamente afectada en los tiempos de respuesta por la gran cantidad de hilos vivos que tiene y finalmente caerse.
Solución
Para evitar este problema, es importante aceptar que los Timeout ocurren, y no solo eso, que pueden ocurrir mucho más de lo que nos gustaría, y es por ello que, en lugar de tratar de ocultar el problema, es mejor aprender a lidiar con ello, es por esto que, lo primero que debemos de hacer cuando consumimos recursos externos, es siempre definir un tiempo de espera máximo, de esta forma, somos nosotros los que cortamos la comunicación y procedemos con un plan B.
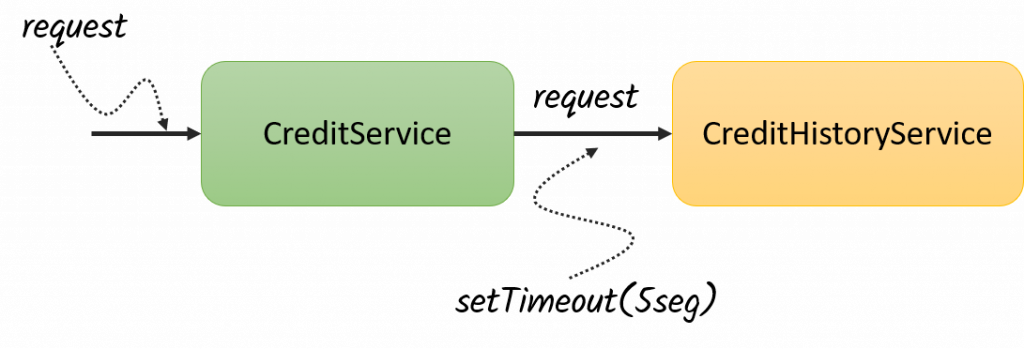
En esta nueva estrategia, siempre que lanzamos un request, definimos el tiempo de espera que estamos dispuesta a tolerar y si este tiempo de espera se excede, entonces cortamos la comunicación y hacemos algo en consecuencia. Dado que no podemos aprobar o rechazar la solicitud de crédito en ese momento, no podríamos darle una respuesta al cliente de inmediato, pero tampoco tendría necesariamente terminar en un error, ya que en lugar de regresarle un error, podríamos guarda la solicitud, decir al cliente al cliente que estamos procesando su solitud y que más tarde le notificaremos el resultado de la autorización.
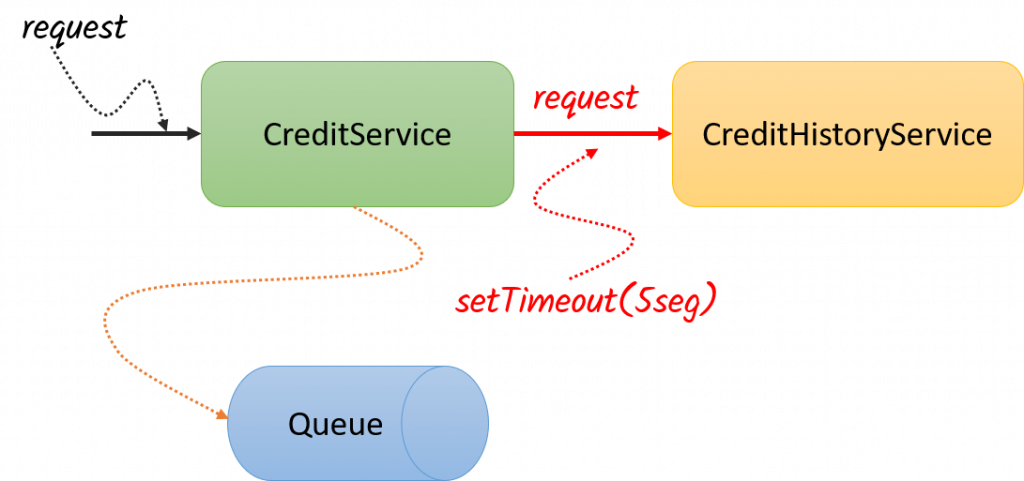
Con esta nueva arquitectura no solo hemos quedado bien con nuestro cliente, si no que evitamos que los hilos de ejecución se acumulen en nuestro servidor, evitando que este degrade sus tiempos de respuesta o finalmente muera.

Conclusiones
Como programadores siempre queremos asumir que todos los servicios responderán correctamente, y de esta forma lavarnos las manos diciendo que si nuestro servicio falla, es por culpa de otros, sin embargo, nuestra responsabilidad como buenos desarrolladores es hacer aplicaciones resilientes, que puedan recuperarse ante un error y responder adecuadamente.
Como hemos analizado en este artículo, nunca hay que asumir que todos puede salir mal, al contrario, siempre hay que ser desconfiados y plantearnos que pasarían ante un error, en este caso, ante un Timeout.
Es super importante la aplicación de los Timeouts cuando se manejan los MEPs (Patrones de Mensajería), específicamente en el caso de los de tipo Síncronos o también llamados Request/Response, para evitar que la conexión se quede pegada más de la cuenta generando un consumo innecesario de recursos. Complemento que el manejo de los Timeouts debe ser “incremental” con relación al # de servicios.
Ejm: Timeout “Service Consumer” = Sumatoria tiempo “Service Provider” + tiempo de “Servicios Hijos”.
Tu observación es correcta, es importante acumular los tiempos de respuesta
Gracias por los buenos consejos y buenas prácticas de diseño
Por nada, y gracias por el comentario 😀
Muy buenos tus aportes, gracias.
Gracias a tí por el comentario 🙂
Excelente apreciación del concepto
Lo aplicaré a mi software
Gracias por el aporte.
Me parece buena esta formula que comentaron,
Ejm: Timeout “Service Consumer” = Sumatoria tiempo “Service Provider” + tiempo de “Servicios Hijos”.
Adicional sumaria un tiempo extra por los tiempos de conexión y red entre los servicios.
Así como los “Service Provider” pueden tener un procesamiento adicional si no entregan respuesta y necesitan realizar rollback de lo que se realizo y no haber entregado respuesta.
Claro, el tiempo que pasa desde que lanzamos el request, hasta que recibimos el primer bit, se llama latencia, la latencia contempla TODO.
Lo del rollback, bueno, eso sería otro tema, incluso, en arquitecturas distribuidas no existe el rollback
En el material de tu autoría, está contemplado algún conjunto de buenas prácticas para soluciones basadas en microservicios? Me llama la atención esa parte de la inexistencia de rollback y en ese sentido qué sería lo mejor? Por ejemplo se me ocurre un patrón que es conocido como “Command” mismo que podría hacer esa simulación de rollback
En entornos distribuidos no existe el rollback, porque la llamada a un servicio es atómica, es decir, que cada servicio que invocas crea y cierra sus propias transacciones, por lo que si algo falla, es necesario aplicar algo llamado compensación, que es básicamente ejecutar otros servicios para deshacer lo que ya está hecho en otro sistema, también puedes usar un patrón llamado Saga, pero la verdad es que la mejor estrategia es tratar de recuperarse del error, antes de hacer eso