
 Hasta el momento solo hemos trabajado con el Entity Manager para realizar las operaciones básicas, pero existen detalles más finos que es necesario entender para convertirnos en expertos de JPA. Cuando trabajamos con JPA es común interactuar con el Entity Manager, ¿pero que tanto sabemos acerca de los Persistence Context en realidad?
Hasta el momento solo hemos trabajado con el Entity Manager para realizar las operaciones básicas, pero existen detalles más finos que es necesario entender para convertirnos en expertos de JPA. Cuando trabajamos con JPA es común interactuar con el Entity Manager, ¿pero que tanto sabemos acerca de los Persistence Context en realidad?
Primero que nada, tenemos que saber que el Persistence Context se crea mediante un Persistence Unit y el Entity Manager se crea a partir de un Persistence Context, veamos la siguiente imagen para entender mejor:
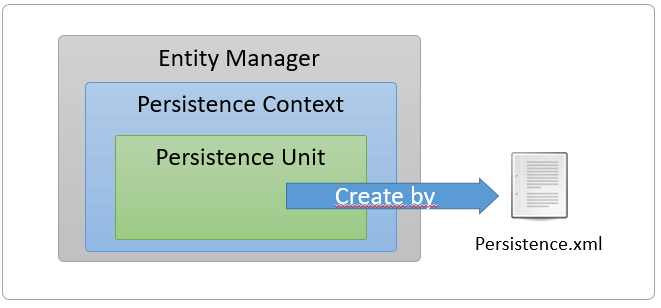
Veamos que todo parte del archivo persistence.xml del cual ya hablamos anteriormente, en este archivo se definen los Persistence Unit, y mediante estos es creado el Persistence Context, el Persistence Context tiene la finalidad de delimitar el alcance de las transacciones, pero también está delimitado a administrar las Entidades definidas por el Persistence Unit con el que fue creado. Adicionalmente, el Entity Manager hace referencia a un Persistence Context el cual será utilizado para administrar las entidades y las transacciones.
Una de las ventajas de tener varios Persistence Unit, es que nos permite definir diferentes configuraciones para cada uno, de esta manera podemos delimitar las entidades de cada módulo e incluso una configuración de base de datos diferentes para cada uno.
Container-Managed Entity Manager
Básicamente existen dos formas de trabajar con JPA, la más simple es cuando lo utilizamos en aplicaciones SE o de escritorio y la segunda forma que es la que estudiaremos en esta sección, es cuando lo utilizamos en ambientes de Java EE con EJB.
La principal característica de utilizar Entity Manager administrado por el contenedor, es que es el mismo Container el que se encarga de abrir y cerrar las transacciones, por lo que el programador solo se preocupa por implementar la lógica de negocio despreocupándose en la totalidad de las transacciones.
En ambientes Java EE se suele utilizar la anotación @PersistenceContext para crear el EntityManager, como veremos en el siguiente EJB.
package com.obb.jpa.jpaturorial.entitymanager;
import javax.ejb.*;
import javax.persistence.*;
/**
* @author Oscar Blancarte
*/
@EJB
@Stateless
public class EmployeeDAO implements IEmployeeDAO{
@PersistenceContext(unitName = "JPA_PU")
private EntityManager manager;
}
Cuando utilizamos la anotación @PersistenceContext el contenedor inyecta de forma automática una referencia válida del EntityManager creado a partir de la Persistence Unit JPA_PU, de esta forma, el programador podrá utilizar el EntityManager en cualquier método que defina, y las transacciones será administradas de forma automática.
Ahora bien, existen dos variantes de los Container-Managed, Transaction-Scope y Extended, los cuales son utilizados en circunstancias diferentes. Para utilizar una variante o la otra, es necesario definirlo en la anotación @PersistenceContext mediante la propiedad type. Los valores posibles son TRANSACTION y EXTENDED como veremos a continuación:
@PersistenceContext(unitName = "JPA_PU", type = PersistenceContextType.TRANSACTION) @PersistenceContext(unitName = "JPA_PU", type = PersistenceContextType.EXTENDED)
En caso de no definir la propiedad type, el valor por default será TRANSACTION, lo cual está bien, porque es por lejos la variante más utilizada.
Transaction-Scope
La variante Transaction-Scope es la variante utiliza por default, por lo que no es necesario definir la propiedad type para utilizarla. Esta variante tiene la particularidad de que el contexto de persistencia solo será válido durante le ejecución de la operación de negocio, una vez que la operación termine el contexto de persistencia se destruye y todas las entidades relacionadas con el Entity Manager será descartadas.
Este tipo de estrategias se utiliza para EJB sin estado como los @Stateless, pues cada invocación a una operación de negocio se espera que realice una acción, persista y retorne un resultado, y cada ejecución tendrá un contexto de persistencia diferente, garantizando de esta forma que el servicio siempre arroje el mismo resultado para la misma entrada.
Veamos un ejemplo de un servicio de creación de empleados:
package com.obb.jpa.jpaturorial.entitymanager;
import com.obb.jpa.jpaturorial.entity.Employee;
import javax.ejb.*;
import javax.persistence.*;
/**
* @author Oscar Blancarte
*/
@EJB
@Stateless
public class EmployeeDAO implements IEmployeeDAO{
@PersistenceContext(unitName = "JPA_PU", type = PersistenceContextType.TRANSACTION)
private EntityManager manager;
@TransactionAttribute(TransactionAttributeType.NEVER)
public Employee getEmployeeById(Long empId){
//Se consulta el empleado mediante el ID
return manager.find(Employee.class, empId);
}
@TransactionAttribute(TransactionAttributeType.SUPPORTS)
public void updateEmployeeName(Long empId, String newName){
//El empleado es nuevamente consultado de la base de datos
//debido a que cada invocación es un nuevo contexto de persistencia
Employee emp = manager.find(Employee.class, empId);
emp.setName(newName);
//Al termina el método, el contenedor realiza un Commit automático.
}
}
Imaginemos el siguiente escenario, tenemos una aplicación que carga el empleado en pantalla utilizando el método getEmployeeById, esta consulta al empleado mediante el ID y lo retorna, la aplicación utiliza el empleado consultado para mostrarlo en pantalla, luego, modificamos el nombre del empleado y guardamos los cambios mediante el método updateEmployeeName.
Lo primero que hace la aplicación es consultar el empleado, hasta aquí todo bien, pero cuando actualizamos el nombre del empleado, vemos que realizamos un find mediante el ID del empleado, podríamos pensar que como ya lo hemos consultado anteriormente mediante el método getEmployeeById este solo lo retomará del cache sin realizar una nueva consulta a la base de datos, sin embargo, Transaction-Scope garantiza que cada ejecución crea un nuevo PersistenceContext en blanco, por lo que el empleado que anteriormente ya habíamos consultado será nuevamente consultado, debido que en la segunda llamada al método updateemployeeName el Persistence Context está en blanco.
No te preocupes por las anotaciones @TransactionAttribute, más adelante las explicaremos por ahora pasémoslas por alto.
Extended
La segunda variante es Extended, que como su nombre nos lo indica, se trata de un Contexto de Persistencia Extendido, donde el contexto persistirá durante todo el tiempo de vida de la sesión, sin importar el número de operaciones o transacciones que se realicen.
A diferencia de Transaction-Scope, en esta variante todos los cambios realizados en el Persistence Context seguirán vigentes, por lo que cada ejecución que realicemos se favorecerá de las ejecuciones pasadas.
Este tipo de variante es utilizada cuando trabajamos con EJB con sesión como el @Stateful, veamos el mismo ejemplo anterior pero esta vez utilizando un EJB con sesión y la variante Extended.
package com.obb.jpa.jpaturorial.entitymanager;
import com.obb.jpa.jpaturorial.entity.Employee;
import javax.ejb.*;
import javax.persistence.*;
/**
* @author Oscar Blancarte
*/
@EJB
@Stateful
public class EmployeeExtendedDAO implements IEmployeeDAO{
@PersistenceContext(unitName = "JPA_PU", type = PersistenceContextType.EXTENDED)
private EntityManager manager;
@TransactionAttribute(TransactionAttributeType.NEVER)
public Employee getEmployeeById(Long empId){
//Se consulta el empleado mediante el ID
return manager.find(Employee.class, empId);
}
@TransactionAttribute(TransactionAttributeType.SUPPORTS)
public void updateEmployeeName(Long empId, String newName){
//El empleado no es consultado, debido a que ya fue consultado previamente
Employee emp = manager.find(Employee.class, empId);
emp.setName(newName);
//Al termina el método, el contenedor realiza un Commit automático.
//Los camibios realizados seguiran estando disponibles
}
}
En este caso las cosas son un poco diferentes. Primero que nada, se realiza la consulta del empleado mediante el método getEmployeeById y el empleado es retornado, cuando la ejecución del método termina, el Persistence Context continúa existiendo, por lo que cuando se realiza la actualización del nombre del empleado y se realiza la consulta del empleado, el Entity Manager ya no consulta al empleado, pues este ya fue consultado en el método anterior. Finalmente, el nombre es actualizado y al terminar el método se hace un commit de la transacción. Al finalizar el método el Contexto de persistencia continua activo hasta que la sesión finaliza.
Application-Managed Entity Manager
La segunda forma de trabajar con JPA es delegar al programador la responsabilidad de administrar las transacciones, este escenario se da con mucha más frecuencia en aplicaciones de escritorio, aunque existen escenarios donde es utilizado en entornos de Java EE.
Básicamente el programador tiene que crear el EntityManager a través del EntityManagerFactory y tiene que abrir y cerrar las transacciones cada vez que requiera.
Veamos cómo quedaría el escenario anteriormente planteado utilizando application-managed:
package com.obb.jpa.jpaturorial.entitymanager;
import com.obb.jpa.jpaturorial.entity.Employee;
import javax.ejb.*;
import javax.persistence.*;
/**
* @author Oscar Blancarte
*/
public class EmployeeApplicationDAO {
private EntityManager manager;
public EmployeeApplicationDAO() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("JPA_PU");
manager = emf.createEntityManager();
}
public Employee getEmployeeById(Long empId) {
return manager.find(Employee.class, empId);
}
public void updateEmployeeName(Long empId, String newName) {
//Se abre la transacción manualmente
manager.getTransaction().begin();
Employee emp = manager.find(Employee.class, empId);
emp.setName(newName);
//Se cierra la transacción manulamente
manager.getTransaction().commit();
}
}Podemos apreciar que el constructor de la clase estamos creando manualmente el EntityManager en lugar de simplemente inyectarlo como el Container-Managed, la otra diferencia es en el método updateEmployeeName, ya que para poder persistir los cabios tenemos que abrir y cerrar la transacción con los métodos beign y commit.
Buena tarde, tengo dos unidades de persistencias en mi proyecto y dos daos que crean un entitymanager apuntando cada cual a una unidad de persistencia, requiero hacer un join con tablas que se encuentran en cada una de las unidades de persistencias, pero al realizarla sobre un entitymanager me dice que la otra tabla o vista no existe.
saludos!
Si este error es normal por que seguramente solo tienes una entidad en cada PU, lo que tendrias que hacer en tal caso, es registrar las dos Entity en el PU donde necesites hacer el join. De lo contrario, el PU no podra resolver la segunda entidad
Excelente articulo!
Gracias Marcelo 🙂
Buenas tardes, tengo una aplicacion web montada en un servidor
y en otros dos servidores tengo montado un .ear, el detalle esta en que
desde la aplicacion web actualizo valores de una tabla en base de datos, pero
al consumir los servicios que estan en el .ear, este consulta dichos valores y pareciera como si no hubiesen sido
actualizados,(cosa que ocurrió desde la aplicacion) o si estuviera trabajando con valores antiguos, me doy a entender?
Que habria que checar ahi? o que se puede hacer?
Gracias de antemano
Hola Inho, me imagino en que los EAR’s utilizas JPA, y me imagino que balanceas la carga entre los dos EAR’s, es correcta mi premisa?
Si eso es así, lo más seguro es que sea un problema de cache, pues JPA internamente cachea la información para mejorar su rendimiento, por lo que cualquier información que actualice un servidor (EAR) el otro la puede tener en cache con los valores anteriores, pero como no se entera de que cambio, entonces no actualiza la información.
Una pregunta, los servidores están en cluster o solo los pusiste a funcionar de forma independiente? en Cluster puede implementar una estrategia para compartir el cache, pero en servidores independientes, tendrás que refrescar las entidades cada vez que requieres utilizarlas, para asegurarte de tener siempre la ultima versión.
Saludos.
Mi hermano, explicas muy bien, bastante claro.
No dejes de publicar.
Si es posible lanza un articulo sobre jpa con dos bases de datos unidas por una clave foránea.
Muchas Gracias.
Hola Julio, gracias por el comentario.
No querrás decir tablas unidas por una clave foránea?
saludos.
Hola Oscar,
Muchas gracias por tu post, excelente explicación.
Pude hacer funcionar el método find gracias a tu ejemplo pero estoy teniendo un problema con el metodo persist del Entity Manager, no me marca ningún error pero no persiste en la base de datos, estoy utilizando transaction-type=”JTA”. ¿Podrías ayudarme ?
Hola Emmanuel, si estás utilizando JTA es por que estás utilizando JPA dentro de un EJB container, en tal caso el contenedor es el que se encarga de abrir y cerrar las transacciones, si lo estás ejecutando desde una app standalone deberás usar
RESOURCE_LOCALy controlar las transacciones manualmente medianteEntityManager.getTransaction().begin()ygetTransaction().commit().Me podrías confirmar si estás utilizando EJB o estás utilizando una app standalone?
saludos.
Hola Óscar!
Una duda. Es posible tener 2 EntityManager creadas? Es decir, con el mismo PU crear una entitymanager para poder hacer .commit() y .begin() y otra para crearlo a través del EntityManager únicamente. No sé si me he explicado.
Gracias!
Si, es totalmente posible, tu puedes crear cuantos entityManager quieras, pero la verdad no entiendo para que quieres dos, yo en casi 15 años usando JPA jamás he necesitado dos entityManager, mas bien yo creo que algún concepto tienes errado.
Buenos días Oscar,
Mi nombre es Luis Alberto Carmona y tengo el siguiente caso:
Ambiente: NetBeans 8.2, JSF 2.2, Primeface 5.0, JPA 2.x, EJB 3.X, Glassfish 4.1.1., Criteria API, JAVE EE 7
Estoy haciendo un proceso en una clase @Stateless , en ella hay un método que lee una tabla y por cada registro que cumpla unas condiciones, se crea un registro en otra tabla. Esto lo está realizando bien.
El problema que se presenta es es el siguiente:
Cuando el proceso supera los dos (2) minutos, se dispara el RollBack. Como se le puede dar más tiempo al proceso para que termine su tarea, sin que se presente el problema ?.
Cuando se presentan procesos en aplicaciones web, como seria la manera de programarlos?
gracias.
hola Luis, puedes agregar una propiedad para incrementar el timeout en el archivo persistence.xml, aun que no recuerdo el nombre de la propiedad, sería cuestión de buscar en Google, la otra opción es agregar un Hint al Query, para que incremente el timeout, pero tendrás que revisar la documentación para ver cual es el hint.
Hola Luis.
Estoy trabajando en un proyecto con wildfly en el que defino las conexiones a las BDs en el datasource, en mi app deseo generar por programa un EntityManager sin tener que definir el archivo persistence.xml.
Alguna idea de cómo poder crear el EntityManager para no depender del archivo xml?
Gracias por su ayuda.